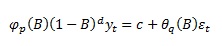The Dickey-Fuller test is a unit root test. Presence of unit root is only one of potential causes of
non-stationarity, therefore in the strict sense it is not a comprehensive stationarity test.
The hypotheses are set in following way:
H0: unit root is present in the sample
H1: stationarity or trend-stationarity
Definition of unit root is based on characteristic equation. Having autoregressive process (with zero-mean, no autocorrelation and constant variance error
εt):
Then
m is root of characteristic equation:
If
m=1 then it is a unit root.
In case of first order autoregressive process the characteristic equation becomes:
In this example, the
m is unit root (
m=1) if just when
γ1=1.
If there is unit root in this first order autoregressive process, the process is non-stationary (it is integrated of order one I(1)) as its properties depend on particular time t:
Therefore to test unit root presence in first order autoregressive process AR(1):
Depending on what is the hypothesis, the testing regression model differs:
If hypothesis is a unit root process:
If hypothesis is a unit root process with drift:
If hypothesis is a unit root process with drift and time trend:
We are testing whether δ=0 (γ=δ+1=1), that is null hypothesis of unit root presence. However the testing statistic t does not have standard distribution. Instead Dickey-Fuller distribution tables have to be used (which are specific for each of three stated null hypothesis).
Apparently the test has low power (ability to reject the null if alternative is true) because it’s difficult to distinguish unit root from root near but less than one. It is therefore encouraged to really follow “graphics” and “common sense” before performing actual hypothesis test (
Bo Sjo: Testing for Unit Roots and Cointegration).
To decide which of the tree variants of test shall be used, it’s best to rely on the knowledge about the nature of time series (is the presence of intercept or slope a rational expectation given the time series?). If such knowledge is missing, other approaches can be considered (
Dolado, Jenkinson, Sosvilla-Rivero: Cointegration and Unit Roots).
Since the null hypothesis is non-stationarity (while in some other tests the null is stationarity, e.g. KPSS test), it is good idea to apply Dickey-Fuller test anytime we have good reason to believe the series is non-stationary (
Bo Sjo: Testing for Unit Roots and Cointegration).
We are testing whether time series is
I(1) - integrated of order one. If the time series is already differenced we are testing
I(2). In such case if the
I(2) is not rejected then it makes no sense to test for I(1) anymore.
The Augmented Dickey-Fuller test is a natural extension of the simple test by adding p lags to the process, hereby considering autoregression beyond first order:
Setting order
p is an interesting question though. It is suggested to start with higher lags and cut it down continually. Alternatively information criteria (AIC, BIC, …) can be used.
The R
adf.test function that is often used tests the third form of hypothesis (incl. intercept and slope). The R
ur.df or
adfTest functions enables choosing of appropriate null hypothesis.